
Federated Code Submission Format
This page documents the submission format for your federated solution code for Track A: Financial Crime. Exact submission specifications may be subject to change until submissions open. Each team will be able to make one final submission for evaluation. In addition to local testing and experimentation, teams will also have limited access to test their solutions through the hosted infrastructure later in Phase 2. More details will be provided when submissions open.
The full source code and environment specification for how your code is run is available from the challenge runtime repository.
What to submit
Your submission should be a zip archive named with the extension .zip (e.g., submission.zip). The root level of the archive must contain a solution_federated.py Python module that contains the following named objects:
train_client_factory: A factory function that instantiates a Flower Client for trainingtrain_strategy_factory: A factory function that instantiates a Flower Strategy for trainingtest_client_factory: A factory function that instantiates a Flower Client for inference on test datatest_strategy_factory: A factory function that instantiates a Flower Strategy for inference on test data
Additional details and API specifications for what these factory functions need to create are discussed in the following sections.
Key Concepts
When you make a submission, this will kick off a containerised evaluation job. This job will run a Python main_federated_train.py script which kicks off a Flower Virtual Client Engine simulation to perform federated training. The training main script will import class factory functions from a module that you submit, and then call these factory functions with the necessary dependencies (e.g., appropriate data access) to instantiate your customised Flower classes that implement the logic for your solution. Then, the job will run a Python main_federated_test.py script which kicks off another simulation that performs federated inference on test data. The test main script similarly imports factory functions from your module and calls these factory functions with test time dependencies.

This train–test sequence will be run multiple times on multiple scenarios—each scenario uses the same evaluation dataset but partitioned differently. This will be used to measure how the efficiency and scaling of your solution changes when there are different numbers of partitions.
The source code for the simulation runner and the container image specification is available from the challenge runtime repository.
Flower's Client, Server, and Strategy Abstractions
Flower's design includes a few abstractions structured to match the general concepts in federated learning. You will be implementing your solution's machine learning and privacy techniques to work with the Client and Strategy APIs.
Client classes hold the logic that is executed by the federation units that have access to partitioned data, while the Server class holds the logic for coordinating among the clients and aggregating results. For the server, Flower additionally separates the federated learning algorithm logic from the networking logic—the algorithm logic is handled by a Strategy class that the server dispatches to. This allows Flower to provide a default Server implementation which handles networking that generally does not need to be customised, while the Strategy can be swapped out or customised to handle different federated learning approaches.
When using a Strategy, the federated learning process will be executed with a structure shown in the sequence diagram below with federated fit, federated evaluate, and centralised evaluate stages. These stages can be run repeatedly in multiple rounds. Each message exchange shown in the diagram is a customisable method on the Strategy or Client respectively. The *Ins and *Res types shown are dataclasses that can serve as containers for arbitrary instruction and result data, respectively—you can have the methods on your strategy and clients to send and accept any serialisable data within these containers. The Strategy also can track which round is currently happening and coordinate different actions (e.g., key exchange with clients) in different rounds.
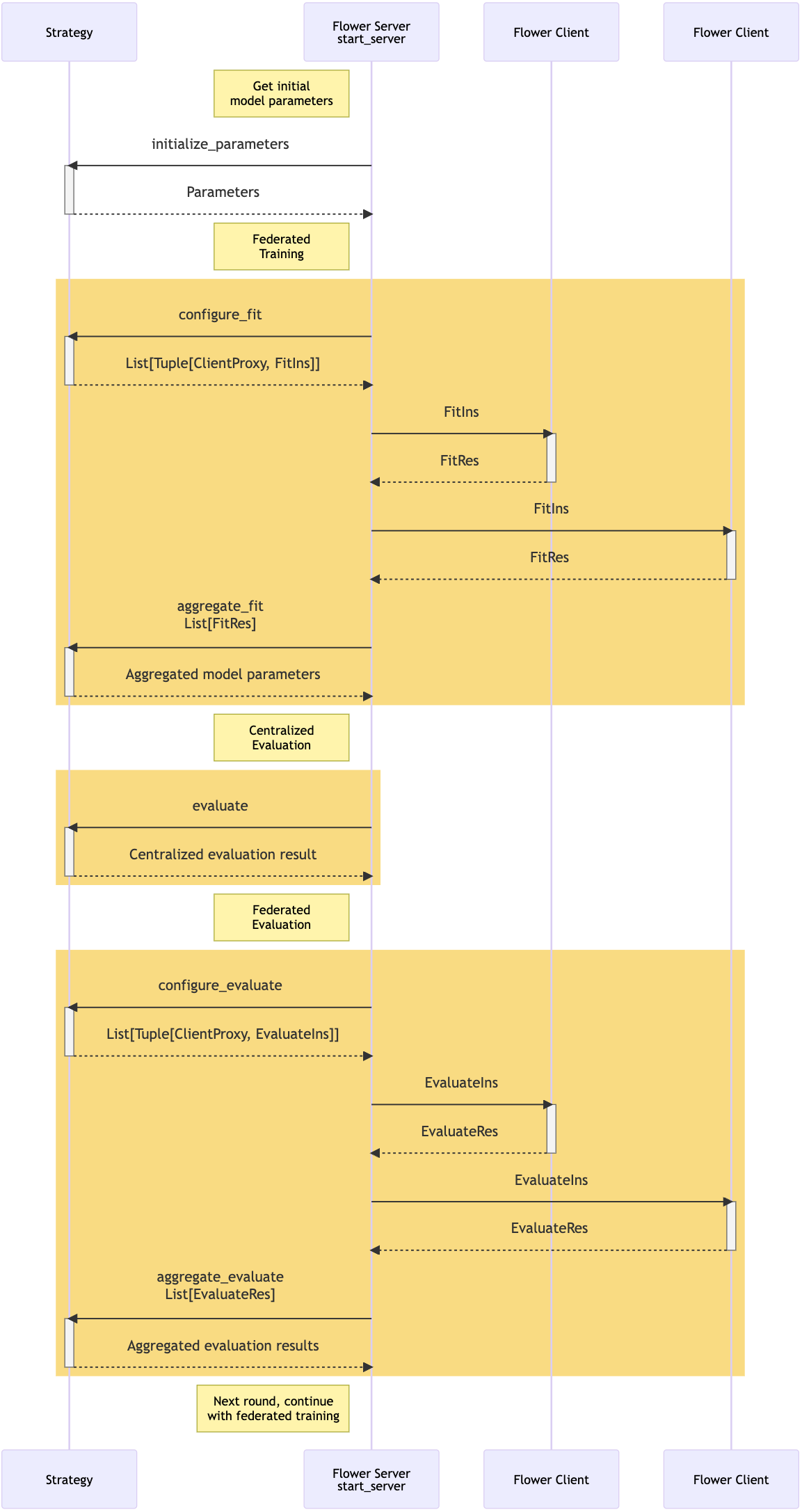
Sequence diagram showing the structure of Flower's federated workflow with the Client and Strategy abstractions. Adapted from "Implementing Strategies" from Flower documentation.
Please review the following documentation and source code to understand the key Flower class APIs and what you need to implement.
Client
To implement a Flower client, you should subclass one of two abstract base classes: flwr.client.Client or flwr.client.NumPyClient. These two base classes have equivalent structure but slightly different input and output APIs on their methods. NumPyClient is a convenience API which allows you to pass lists of numpy arrays as inputs and outputs—the Flower simulation will automatically wrap a NumPyClient in a regular Client and handle serialisation and deserialisation of the numpy arrays. If you do not plan to use numpy arrays in your code, then you may choose to implement a regular Client instead.
References:
- Introduction to Federated Learning tutorial from Flower docs, which shows an example of using a
NumPyClientwith pytorch - Configuring Clients how-to guide from Flower docs
Clientabstract base class API referenceClientabstract base class source codeNumPyClientabstract base class API referenceNumPyClientabstract base class source code
Strategy
To implement a Flower strategy, you should subclass the flwr.server.strategy.Strategy abstract base class.
References:
- Strategies how-to guide from Flower docs
- Implementing Strategies how-to guide from Flower docs
Strategyabstract base class API referenceStrategyabstract base class source codeflwr.server.strategymodule source code—contains source code for Flower-provided strategy implementations
Flower Types and Dataclasses
Flower is thoroughly annotated and documented with Python type annotations. These types are all defined in the flwr.common.typing module. In general, the server sends messages contained in a *Ins instructions dataclass to clients, and the clients send back messages contained in a *Res results dataclass back to the server. You can find definitions of these dataclasses in the typing module. In general, the contents of these dataclasses must be ProtoBuf scalar types, which Flower uses for serialisation and deserialisation.
If you are subclassing NumPyClient, you will notice that the method signatures of the APIs are a little different. Flower automatically unwraps and wraps the contents of the *Ins and *Res dataclasses when using NumPyClient, but otherwise the contents are the same and can be identified by the names. Additionally, Flower automatically handles serialisation and deserialisation for numpy ndarrays to bytearrays. The utility functions used for that can be found in the flwr.common.parameter module.
References:
Data Access and API Specifications
You will need to define custom Client and Strategy subclasses that follow the Flower API and implement the logic for your solution. These will need to be instantiated through factory functions that are called with appropriate data and filesystem access. Specifications for these are detailed in the following sections for train and test stages, respectively. The specifications are different between train and test, so you may accordingly want different Client and Strategy subclasses for train and test stages.
Your code is called with specific scope, data access, and filesystem access. Please note that attempts to circumvent the structure of the setup is grounds for disqualification:
- Your code should not inspect the data or print any data to the logs.
- Your code should not directly access any data files other than what the simulation runner explicitly provides to each client.
- Your code must use the intended Flower APIs for client–server communication. Your code must only use the provided client and server directories for saving and loading state. Any use of other I/O or global variables to pass information between calls is forbidden.
- Your code should not exceed its scope. Directly accessing or modifying any global variables or simulation runner state is forbidden.
If in doubt about whether something is okay, you may email us or post on the forum.
Training
In order to execute training, your submitted solution_federated.py module must contain train_client_factory and train_strategy_factory functions. API specifications are shown below, along with type annotations and explanations of the expected inputs and outputs. These functions should return instances of a custom client class and a custom strategy class that you've implemented for training, respectively. The simulation will call your functions with the appropriate data and filesystem dependencies.
Test-time inference will be run in a separate Python process after training and will not share any in-memory scope with training. This means that you must save your trained model to disk, either with each clients to the respective client_dir directory, or with the server to the server_dir directory that is available to the strategy.
# solution_federated.py
def train_client_factory(
cid: str,
data_path: pathlib.Path,
client_dir: pathlib.Path,
) -> typing.Union[flwr.client.Client, flwr.client.NumPyClient]:
"""
Factory function that instantiates and returns a Flower Client for training.
The federated learning simulation engine will use this function to
instantiate clients with all necessary dependencies.
Args:
cid (str): Identifier for a client node/federation unit. Will be
constant over the simulation and between train and test stages. The
SWIFT node will always be named 'swift'.
data_path (Path): Path to CSV data file specific to this client.
client_dir (Path): Path to a directory specific to this client that is
available over the simulation. Clients can use this directory for
saving and reloading client state.
Returns:
(Union[Client, NumPyClient]): Instance of a Flower Client.
"""
...
def train_strategy_factory(
server_dir: pathlib.Path,
) -> typing.Tuple[flwr.server.strategy.Strategy, int]:
"""
Factory function that instantiates and returns a Flower Strategy, plus the
number of federated learning rounds to run.
Args:
server_dir (Path): Path to a directory specific to the server/aggregator
that is available over the simulation. The server can use this
directory for saving and reloading server state. Using this
directory is required for the trained model to be persisted between
training and test stages.
Returns:
(Strategy): Instance of a Flower Strategy.
(int): Number of federated learning rounds to execute.
"""
...
For more details on the input data files, please see the data overview page.
Test
In order to execute test-time inference, your submitted solution_federated.py module must contain test_client_factory and test_strategy_factory functions. API specifications are shown below, along with type annotations and explanations of the expected inputs and outputs. These functions should return instances of a custom client class and a custom strategy subclass that you've implemented that can perform inference, respectively.
A few additional requirements for the test client and test strategy classes:
- While teams may use the
fitAPI for communications during inference, you should not be doing any additional model fitting on the test data. - You will need to have saved your trained model to the provided
client_dirdirectories and/or theserver_dirdirectory during training. These directories will also be provided to your factory functions during test, so that you can load your saved models. - You should perform inference inside the
evaluatemethod of your test clients. Your client factory function will be called withpreds_format_path, which allows you to read a template CSV file that your predictions should match the format of, andpreds_dest_path, which is where you should be writing your predictions to.
# solution_federated.py
def test_client_factory(
cid: str,
data_path: pathlib.Path,
client_dir: pathlib.Path,
preds_format_path: typing.Optional[pathlib.Path],
preds_dest_path: typing.Optional[pathlib.Path],
) -> typing.Union[flwr.client.Client, flwr.client.NumPyClient]:
"""
Factory function that instantiates and returns a Flower Client for test-time
inference. The federated learning simulation engine will use this function
to instantiate clients with all necessary dependencies.
Args:
cid (str): Identifier for a client node/federation unit. Will be
constant over the simulation and between train and test stages. The
SWIFT node will always be named 'swift'.
data_path (Path): Path to CSV test data file specific to this client.
client_dir (Path): Path to a directory specific to this client that is
available over the simulation. Clients can use this directory for
saving and reloading client state.
preds_format_path (Optional[Path]): Path to CSV file matching the format
you must write your predictions with, filled with dummy values. This
will only be non-None for the 'swift' client—bank clients should not
write any predictions and receive None for this argument.
preds_dest_path (Optional[Path]): Destination path that you must write
your test predictions to as a CSV file. This will only be non-None
for the 'swift' client—bank clients should not write any predictions
and will receive None for this argument.
Returns:
(Union[Client, NumPyClient]): Instance of a Flower Client.
"""
...
def test_strategy_factory(
server_dir: pathlib.Path,
) -> typing.Tuple[flwr.server.strategy.Strategy, int]:
"""
Factory function that instantiates and returns a Flower Strategy, plus the
number of federated learning rounds to run.
Args:
server_dir (Path): Path to a directory specific to the server/aggregator
that is available over the simulation. The server can use this
directory for saving and reloading server state. Using this
directory is required for the trained model to be persisted between
training and test stages.
Returns:
(Strategy): Instance of a Flower Strategy.
(int): Number of federated learning rounds to execute.
"""
...
Predictions Format
Your SWIFT test client should produce a predictions CSV file written to the provided preds_dest_path file path. Each row should correspond to one individual transaction in the test set, identified by the column MessageId. Each row should also have a float value in the range [0.0, 1.0] for the column Score which represents a confidence score that that individual transaction is anomalous. A higher score means higher confidence that that transaction is anomalous. A predictions format CSV is provided via preds_format_path that matches the rows and columns that your predictions need to have, with dummy values for Score. You can load that file and replace the score values with ones from your model.
| MessageId | Score |
|---|---|
| TRWNCKR3FM | 0.5 |
| TRCY616MRF | 0.5 |
| TR45UWDHAW | 0.5 |
| ... |
Bank clients should not write any predictions. Bank clients will receive None values for preds_dest_path and preds_format_path.
Optional: Setup Functions
Added January 11, 2023
An optional setup step will be run before each of federated training and federated inference. You can make use of this step by including train_setup and/or test_setup functions in your solution_federated.py module. The setup functions are intended to make it simpler to perform initial setup between the parties, by avoiding the need for explicit communication routed via the server. For example, a setup function might generate key pairs and initialize each client's state with the public keys of the other parties, or initialize each client's state with a shared symmetric key.
The computation cost of the setup functions will be measured during evaluation, but their communications overhead will not be measured (because the communication they encode is not explicit). The setup function should therefore not implicitly encode significant communications between the parties.
If you use a setup function, your technical report should describe exactly what computation it performs, and what communications it encodes. Reviewers and judges will be instructed to take this description into account when evaluating the performance of your submission—for example, by reducing performance scores if the setup function has been used to hide communications costs that should have been measured during evaluation. This setup step is not provided explicit access to training or test data and should not perform any computation using the data.
If included, train_setup and test_setup functions should have the following function signatures.
def train_setup(server_dir: Path, client_dirs_dict: Dict[str, Path]):
"""
Perform initial setup between parties before federated training.
Args:
server_dir (Path): Path to a directory specific to the server/aggregator
that is available over the simulation. The server can use this
directory for saving and reloading server state. Using this
directory is required for the trained model to be persisted between
training and test stages.
client_dirs_dict (Dict[str, Path]): Dictionary of paths to the directories
specific to each client that is available over the simulation. Clients
can use these directory for saving and reloading client state. This
dictionary is keyed by the client ID.
"""
...
def test_setup(server_dir: Path, client_dirs_dict: Dict[str, Path]):
"""
Perform initial setup between parties before federated test inference.
"""
...
If you have any questions regarding their use, please ask on the community forums.
Runtime specs
Your code is executed within a container that is defined in our runtime repository. The limits are as follows:
- Your submission must be written in Python (Python 3.9.13) and use the packages defined in the runtime repository.
- The submission must complete execution in 11 hours or less (including all scenarios) [updated 2023-01-21]. These numbers may be adjusted based on the final evaluation data.
- The container has access to 6 vCPUs, 56 GB RAM, and 1 GPU with 12 GB of memory.
- The container will not have network access. All necessary files (code and model assets) must be included in your submission.
- The container execution will not have root access to the filesystem.
Requesting additional dependencies
Since the Docker container will not have network access, all dependency packages must be pre-installed in the container image. We are happy to consider additional packages as long as they are approved by the challenge organisers, do not conflict with each other, and can build successfully. Packages must be available through conda for Python 3.9.13. To request an additional package be added to the docker image, follow the instructions in the runtime repository README.
Note: Since package installations need to be approved, be sure to submit any PRs requesting installation by January 11, 2023 to ensure they are incorporated in time for you to make a successful submission.
Optional: install.sh Script
Added January 11, 2023
A bash script named install.sh can be optionally included as part of your submission. If included, this will be sourced before the evaluation process. This is intended to give you flexibility in setting up the runtime environment, such as performing installation steps with dependencies that are bundled with your submission, or setting necessary environment variables. If you use the install.sh script, your code guide should document and justify exactly what is it is doing. You should not be executing any code that represents a meaningful part your solution's logic. Abuse of this script for unintended purposes is grounds for disqualification. If you have any questions, please ask on the community forum.
Happy building! Once again, if you have any questions or issues you can always head over to the user forum!